
#安裝 docker-ce
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum install docker-ce-18.06.0.ce -y
systemctl enable docker && systemctl start docker
# 移除舊版nvidia-docker
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo yum remove nvidia-docker
# 加入repositories
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
# 安裝 nvidia-docker2
sudo yum install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
# 測試
docker run --runtime=nvidia --rm nvidia/cuda:9.0-base nvidia-smi
標籤彙整: cuda
esxi 6.7上面安裝1080ti
今天在一台Dell R740上面安裝Dell製造的1080Ti

在esxi host上面開啟PCI透通後,重開機
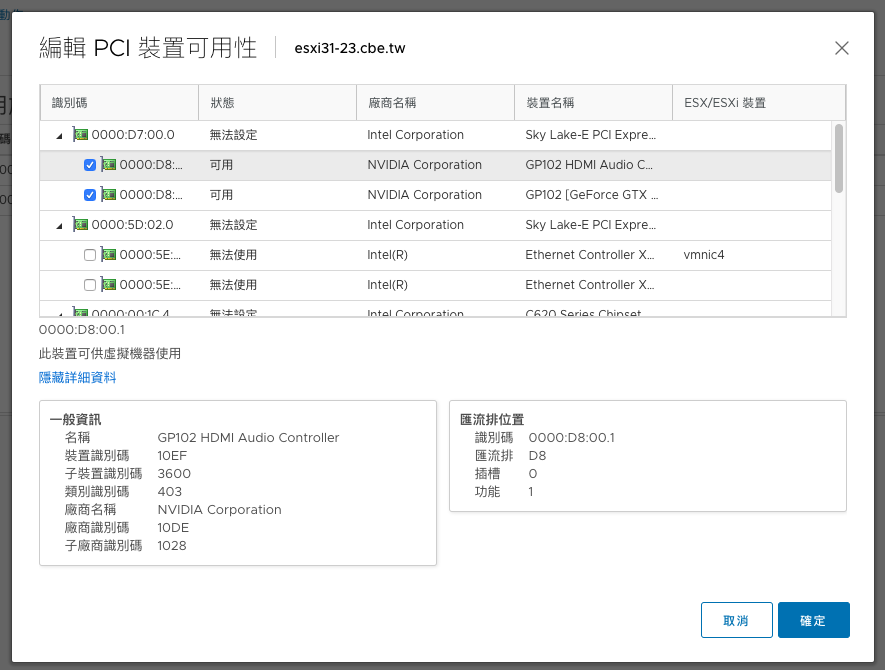
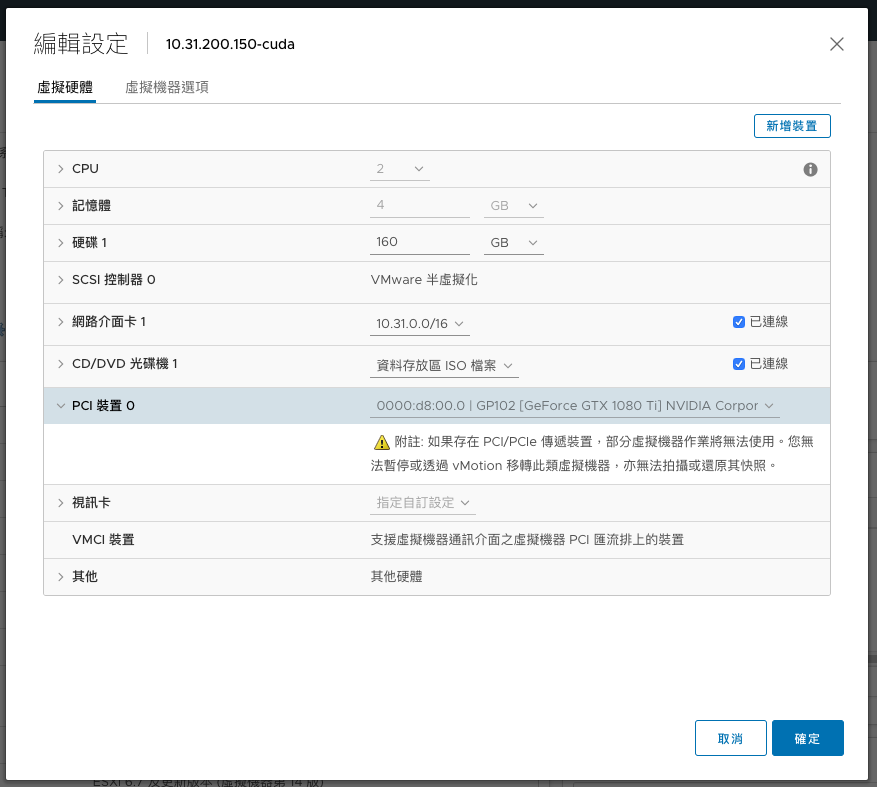
接著在虛擬機上面新增PCI裝置
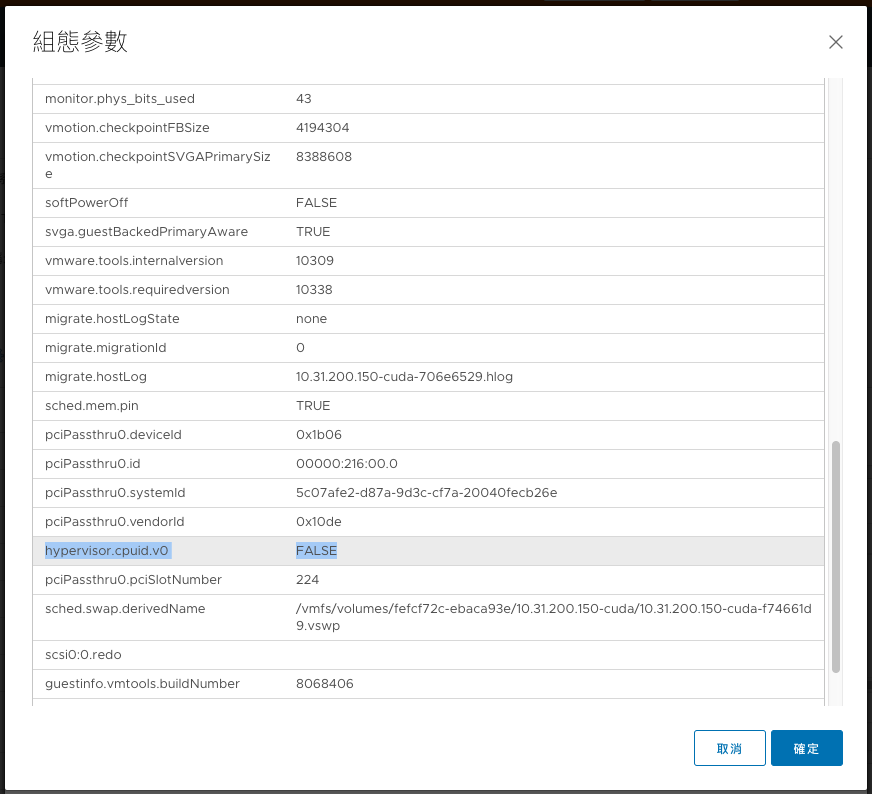
最後再進階設定中加入hypervisor.cpuid.v0=False之設定
就可以在虛擬機內看到GPU了.
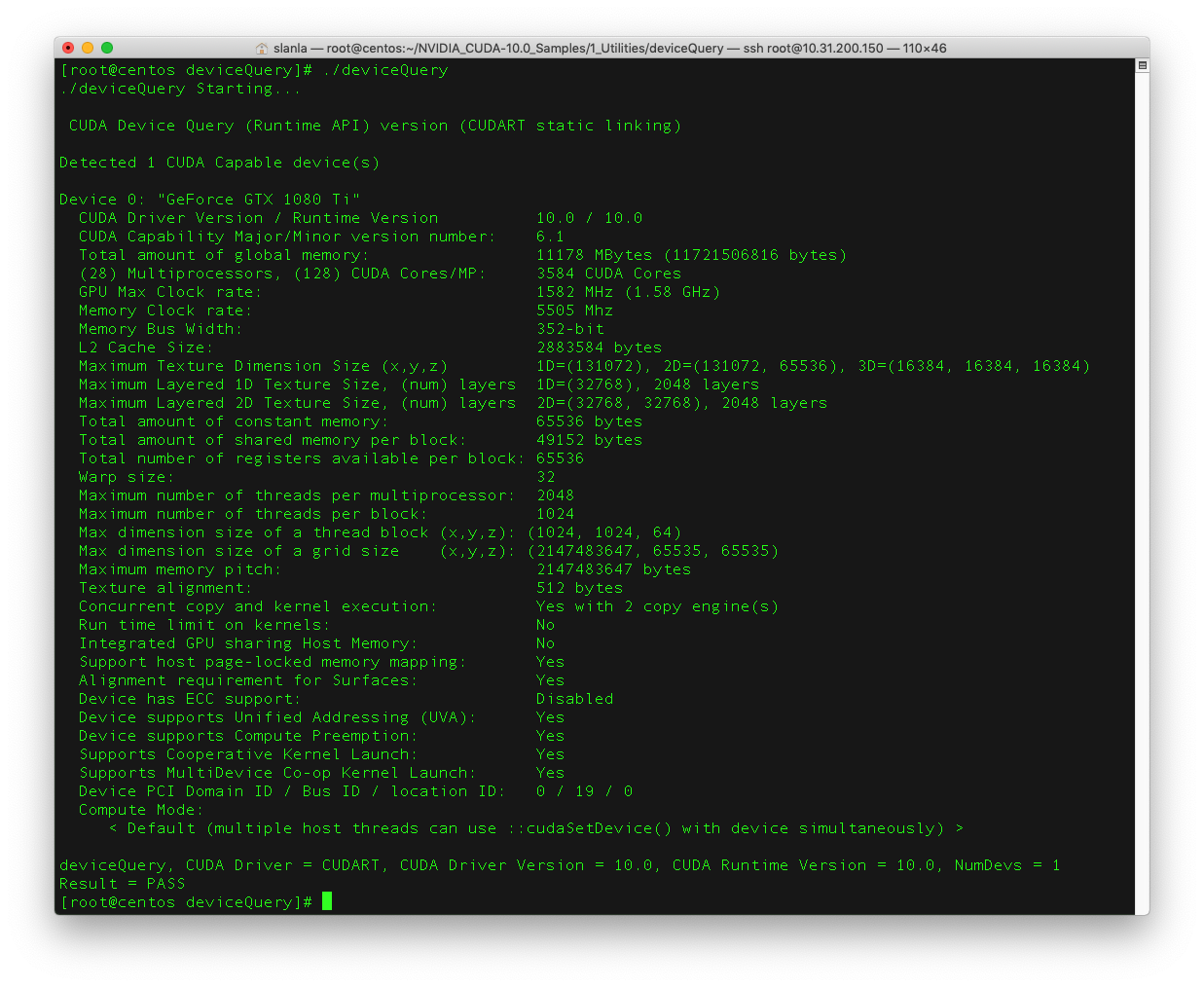
執行CUDA也可以正常.
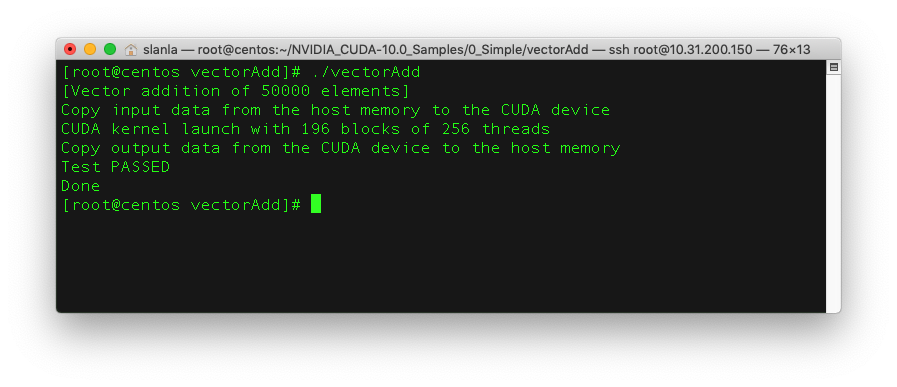
install & test cuda 9.0 on ubuntu 16.04
回覆
安裝
wget https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64-deb
sudo service lightdm stop
sudo dpkg -i cuda-repo-ubuntu1604-9-0-local_9.0.176-1_amd64-deb
sudo apt-key add /var/cuda-repo-9-0-local/7fa2af80.pub
sudo apt-get update && sudo apt-get install cuda -y
sudo reboot
sudo ln -s /usr/local/cuda/bin/nvcc /usr/bin/nvcc
設定環境變數
編輯.bashrc
vim ~/.bashrc
加入
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64:/usr/lib/nvidia-367
export CUDA_HOME=/usr/local/cuda
export PATH=$PATH:/usr/local/cuda/bin
測試編譯
方法1
cd /usr/local/cuda/samples/0_Simple/vectorAdd
make
./vectorAdd
方法2
建立測試檔案vectorAdd.cu
#include <stdio.h>
#include <cuda_runtime.h>
__global__ void vectorAdd(const float *A, const float *B, float *C, int numElements){
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements){
C[i] = A[i] + B[i];
}
}
int main(void){
int numElements = 50000;
//初始化測試資料
float *h_A=new float[numElements];
float *h_B=new float[numElements];
float *h_C=new float[numElements];
for (int i = 0; i < numElements; ++i) {
h_A[i] = rand()/(float)RAND_MAX;
h_B[i] = rand()/(float)RAND_MAX;
}
//配置GPU記憶體空間,並從記憶體中複製資料至GPU中
size_t size = numElements * sizeof(float);
float *d_A = NULL; cudaMalloc((void **)&d_A, size);
float *d_B = NULL; cudaMalloc((void **)&d_B, size);
float *d_C = NULL; cudaMalloc((void **)&d_C, size);
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
//運算
int threadsPerBlock = 256;
int blocksPerGrid =(numElements + threadsPerBlock – 1) / threadsPerBlock;
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements);
//取回運算結果
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
//清除GPU記憶體空間
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
//驗證資料
for (int i = 0; i < numElements; ++i) {
if (fabs(h_A[i] + h_B[i] – h_C[i]) > 1e-5) {
fprintf(stderr, "Result verification failed at element %d!\n", i);
exit(EXIT_FAILURE);
}
}
//清除記憶體
delete d_A;
delete d_B;
delete d_C;
printf("Test PASSED\n");
return 0;
}
接著手動編譯~
/usr/local/cuda-9.0/bin/nvcc \
-ccbin g++ \
-m64 \
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_37,code=sm_37 \
-gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_52,code=sm_52 \
-gencode arch=compute_60,code=sm_60 \
-gencode arch=compute_70,code=sm_70 \
-gencode arch=compute_70,code=compute_70 \
-c vectorAdd.cu -o vectorAdd.o
/usr/local/cuda-9.0/bin/nvcc \
-ccbin g++ \
-m64 \
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_37,code=sm_37 \
-gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_52,code=sm_52 \
-gencode arch=compute_60,code=sm_60 \
-gencode arch=compute_70,code=sm_70 \
-gencode arch=compute_70,code=compute_70 \
vectorAdd.o -o vectorAdd
docker+cuda
筆記一下:
nvidia-docker run -it --rm \
nvidia/cuda \
bash
等同於:
docker run -it --rm \
--device=/dev/nvidiactl \
--device=/dev/nvidia-uvm \
--device=/dev/nvidia0 \
nvidia/cuda \
bash
CUDA rand (use MT19937)
For generator random number every time, we must put a seed from CPU. (eg : time(0))
cuda_kernel<<<grid,block>>>(time(0));
And in the parallel thread, we also use a offset value to generator difference random number in the same time.
c__global__ void cuda_kernel(int seed)
{
int index= (blockIdx.y*blockDim.y+threadIdx.y)*(gridDim.x*blockDim.x)+(blockIdx.x*blockDim.x+threadIdx.x);
MTRand mtrand(seed+index); //seed + offset:index
printf("%5.2f",mtrand.randf(0,10)");
}
MTRand Class code:
class MTRand
{
/*
MT19937
source: http://www.math.sci.hiroshima-u.ac.jp/~m-mat/MT/MT2002/CODES/mt19937ar.c
*/
private:
#define __MTRand_N__ 624
#define __MTRand_M__ 397
#define __MTRand_MATRIX_A__ 0x9908b0dfUL
#define __MTRand_UPPER_MASK__ 0x80000000UL
#define __MTRand_LOWER_MASK__ 0x7fffffffUL
unsigned long mt[__MTRand_N__];
unsigned long mag01[2];
int mti;
__host__ __device__
void init_genrand(unsigned long s)
{
mt[0]= s & 0xffffffffUL;
for (mti=1; mti<__MTRand_N__; mti++) {
mt[mti] = (1812433253UL * (mt[mti-1] ^ (mt[mti-1] >> 30)) + mti);
mt[mti] &= 0xffffffffUL;
}
}
__host__ __device__
unsigned long genrand_int32(void)
{
unsigned long y;
if (mti >= __MTRand_N__) {
int kk;
if (mti == __MTRand_N__+1) init_genrand(5489UL);
for (kk=0;kk<__MTRand_N__-__MTRand_M__;kk++) {
y = (mt[kk]&__MTRand_UPPER_MASK__)|(mt[kk+1]&__MTRand_LOWER_MASK__);
mt[kk] = mt[kk+__MTRand_M__] ^ (y >> 1) ^ mag01[y & 0x1UL];
}
for (;kk<__MTRand_N__-1;kk++) {
y = (mt[kk]&__MTRand_UPPER_MASK__)|(mt[kk+1]&__MTRand_LOWER_MASK__);
mt[kk] = mt[kk+(__MTRand_M__-__MTRand_N__)] ^ (y >> 1) ^ mag01[y & 0x1UL];
}
y = (mt[__MTRand_N__-1]&__MTRand_UPPER_MASK__)|(mt[0]&__MTRand_LOWER_MASK__);
mt[__MTRand_N__-1] = mt[__MTRand_M__-1] ^ (y >> 1) ^ mag01[y & 0x1UL];
mti = 0;
}
y = mt[mti++];
y ^= (y >> 11);
y ^= (y << 7) & 0x9d2c5680UL;
y ^= (y << 15) & 0xefc60000UL;
y ^= (y >> 18);
return y;
}
public:
__host__ __device__
MTRand(int seed)
:mti(__MTRand_N__+1)
{
mag01[0]=0x0UL;
mag01[1]=__MTRand_MATRIX_A__;
init_genrand(19650218UL+seed);
}
__host__ __device__
unsigned long rand()
{
return genrand_int32();
}
__host__ __device__
float randf()
{
return genrand_int32()*(1.0/4294967295.0);
}
__host__ __device__
float randf(float min,float max)
{
if(max<min) { float t=min; min=max; max=t; }
return randf()*(max-min)+min;
}
};